Асимметричная угроза безопасности объектов ТЭК
В последние годы объекты топливно-энергетического комплекса и критической инфраструктуры России подвергаются систематическим атакам с использованием беспилотных летательных аппаратов. Традиционные средства противовоздушной обороны и радиоэлектронной борьбы зачастую оказываются экономически неэффективными против массового применения дешёвых БПЛА.
Основная сложность перехвата заключается в малой заметности дронов, их высокой манёвренности и низкой стоимости. Поражение маневрирующего FPV-дрона стрелковым оружием представляет собой сложнейшую задачу даже для профессиональных стрелков, что подтверждается специализированными испытаниями.
Ограниченная эффективность ручного перехвата
На практике поражение дрона огнестрельным оружием даже на ближних дистанциях составляет серьёзную проблему даже для опытного стрелка-спортсмена .
* Видеодемонстрация сложности перехвата FPV-дрона специалистом мирового уровня.
Типы БПЛА, представляющие угрозу

БПЛА «Бобер»
Тактический разведывательный дрон

БПЛА «Чак»
Компактный FPV-дрон
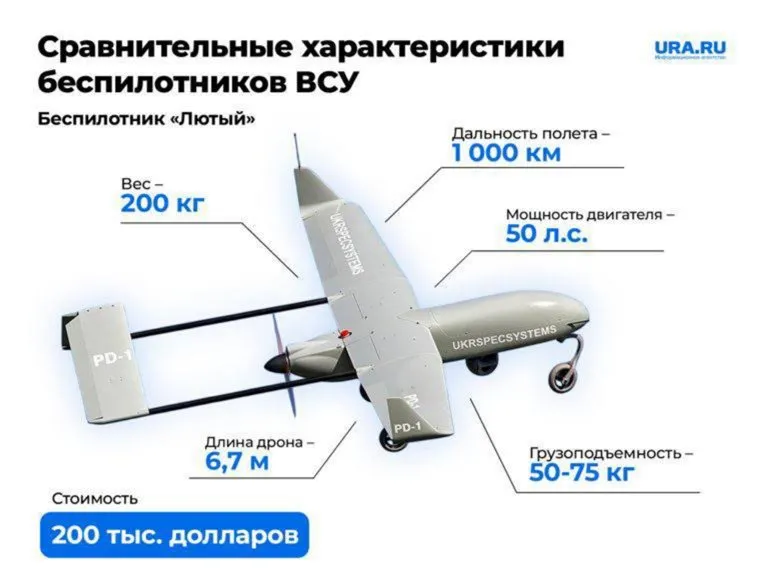
БПЛА «Лютый»
Ударный БПЛА дальнего радиуса

БПЛА «Рубака»
Штурмовой дрон
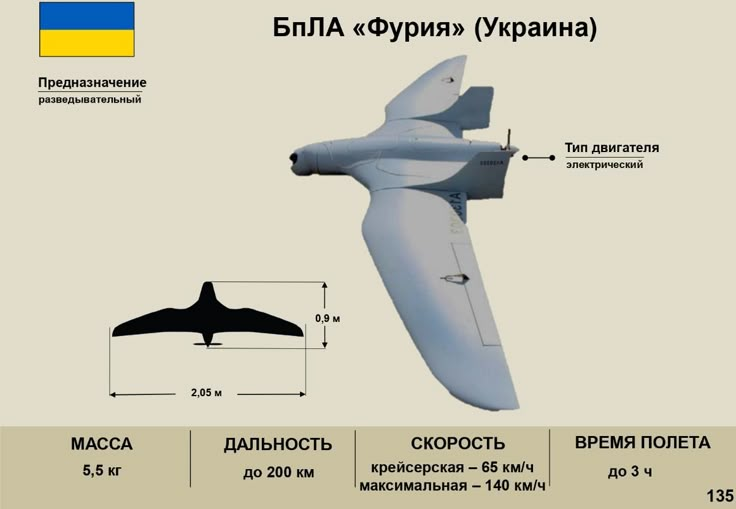
БПЛА «Фурье»
Разведывательный комплекс
Разнообразие угроз
Более 50 типов БПЛА различных классов представляют угрозу объектам ТЭК
Нажмите на изображение для увеличения
Малая заметность
Компактные размеры и специальные покрытия затрудняют обнаружение БПЛА традиционными средствами
Высокая манёвренность
Скорость и способность к резким изменениям траектории делают дроны сложными целями
Экономическая асимметрия
Низкая стоимость атакующих БПЛА делает экономически невыгодным применение традиционных систем ПВО


